Unraveling the Regional Specificities of Malbec Wines from Mendoza, Argentina, and from Northern California


 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials
3. Methods
3.1. Motivation and Algorithm
- Step 1.
- Normalize and generate a digital coding for each of the feature j characterizing the N wines.
- Step 2.
- Compute a mutual entropy E (j,k) between any pair of features j and k. Set this entropy measure to be a distance on the feature space, and use this distance to construct a DCG tree on the features. The clusters identified on the DCG tree form the different groups of synergistic features.
- Step 3.
- Restrict the data matrix D by only keeping the features corresponding to one of the groups identified in step 2. Perform Data Mechanics on this restricted matrix, and build the corresponding heat map. Repeat this procedure for all groups of features from step 2.
- Step 4.
- For each heat map generated in step 3, analyze the clusters of wine identified by the Data Mechanics procedure, contingent to their response values (i.e., region information). For those clusters with high content of wines that have the same response value, analyze the corresponding patterns among the features. Repeat the procedure for all heat maps from step 3.
3.2. Step 1: Normalization and Digital-coding of the Individual Features
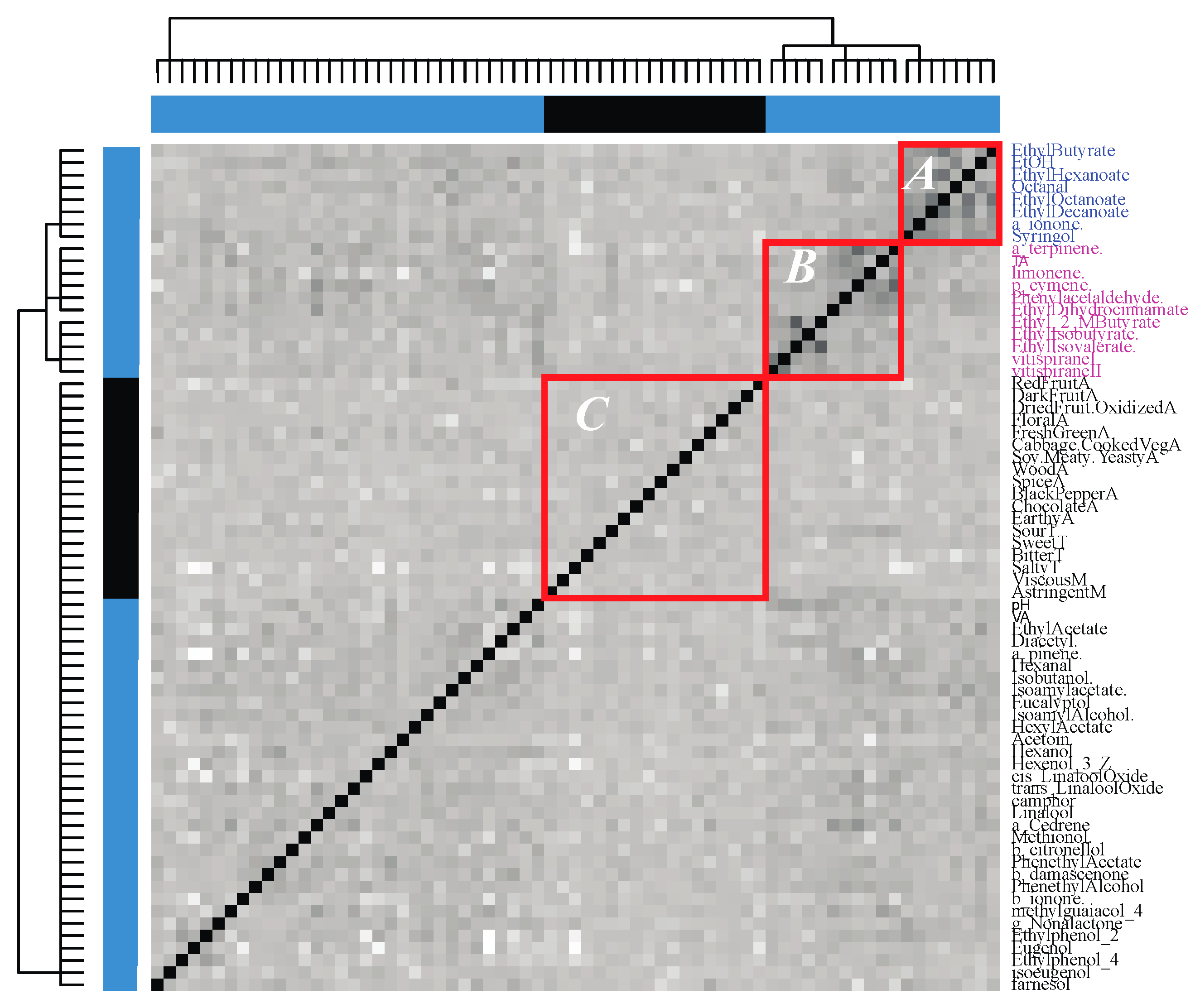
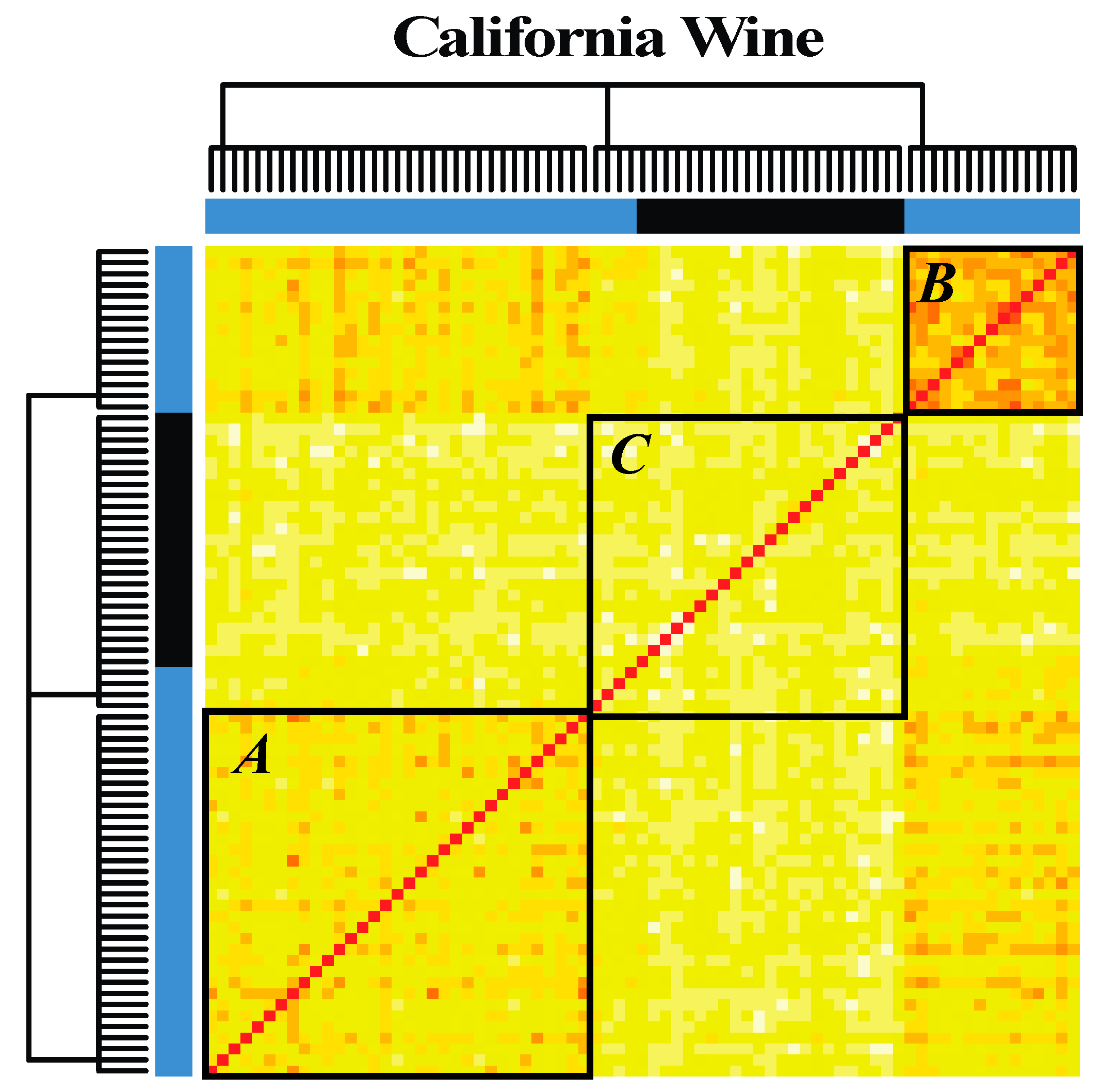
3.3. Step 2: Identification of the Groups of Synergistic Features
3.4. Step 3: Analyzing Patterns between Wines and Features Using Data Mechanics
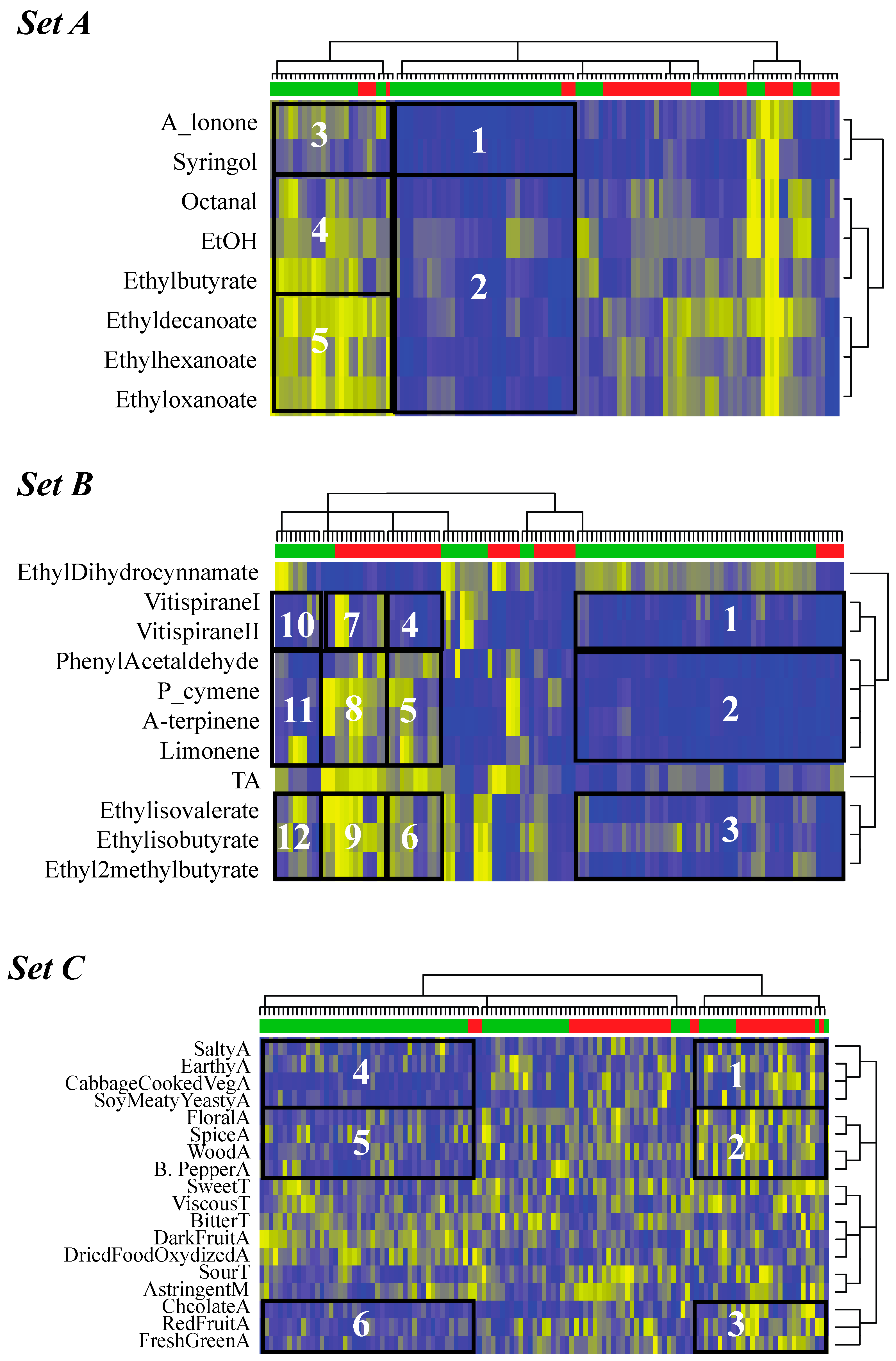
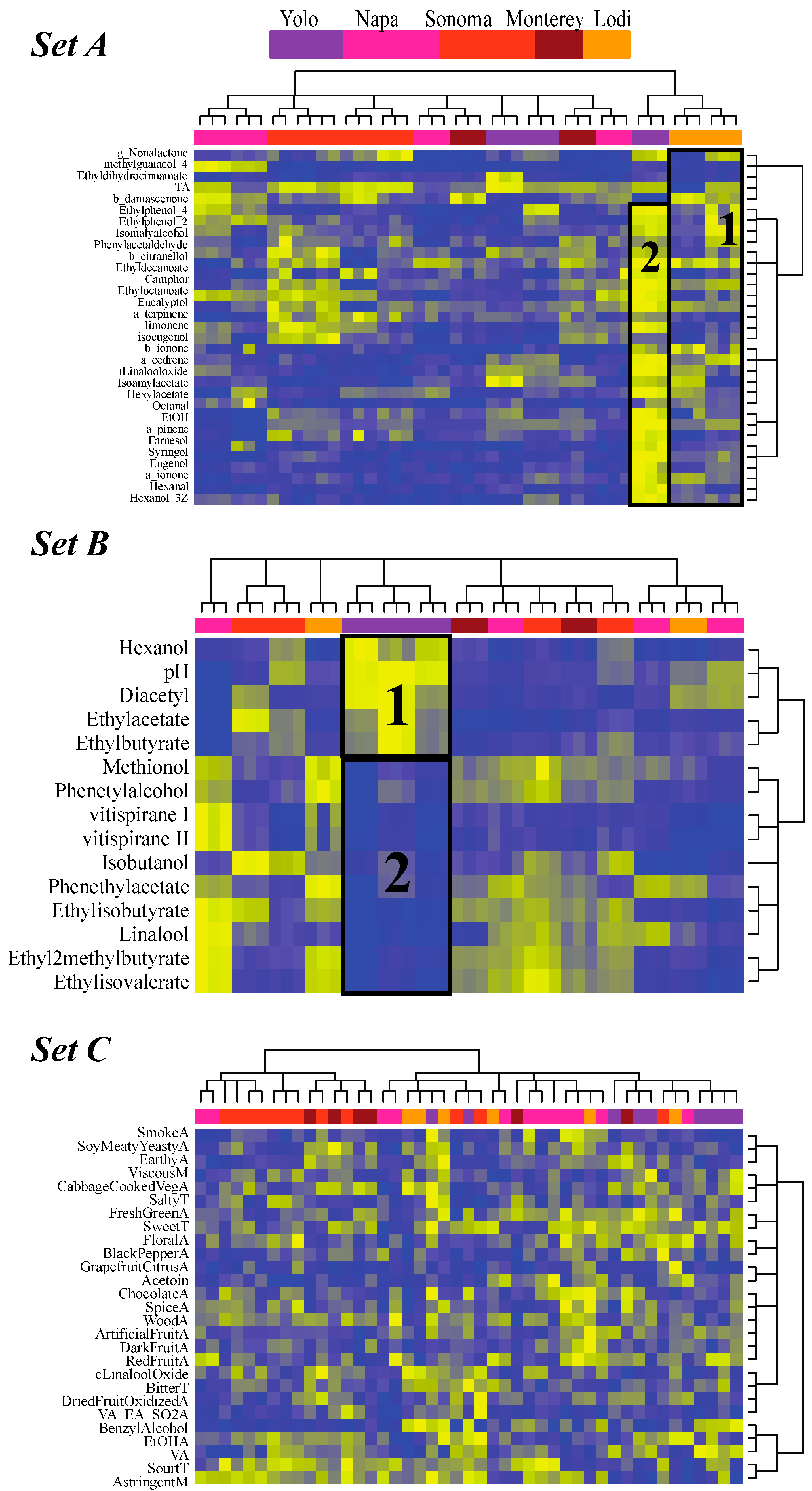
3.5. Step 4: Extracting the Relationships between Features Characterizing Wines and the Regions of Origin of Those Wines
4. Results
4.1. California vs. Argentinan Malbec Wines
4.2. Californian Malbec Wines
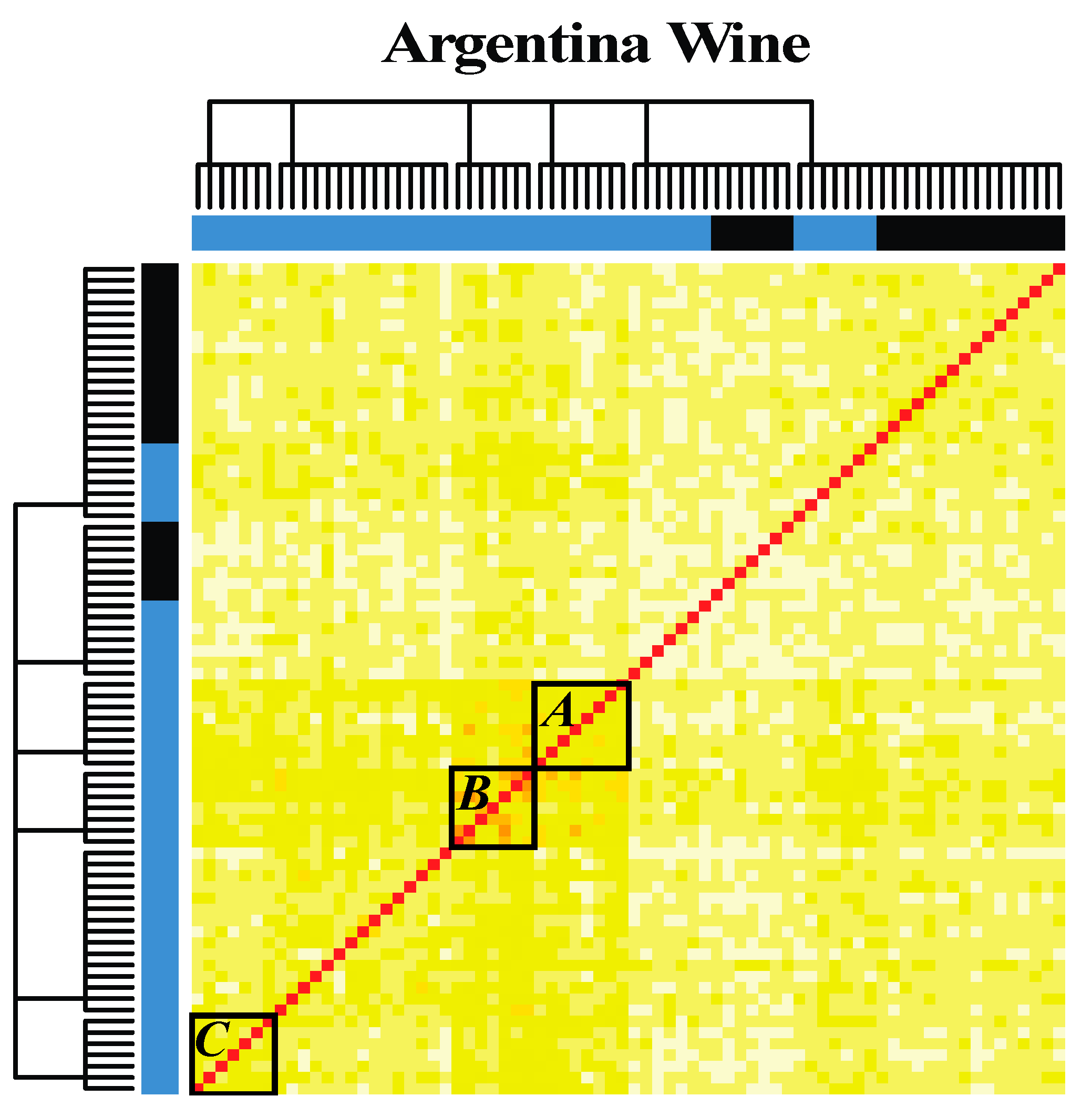
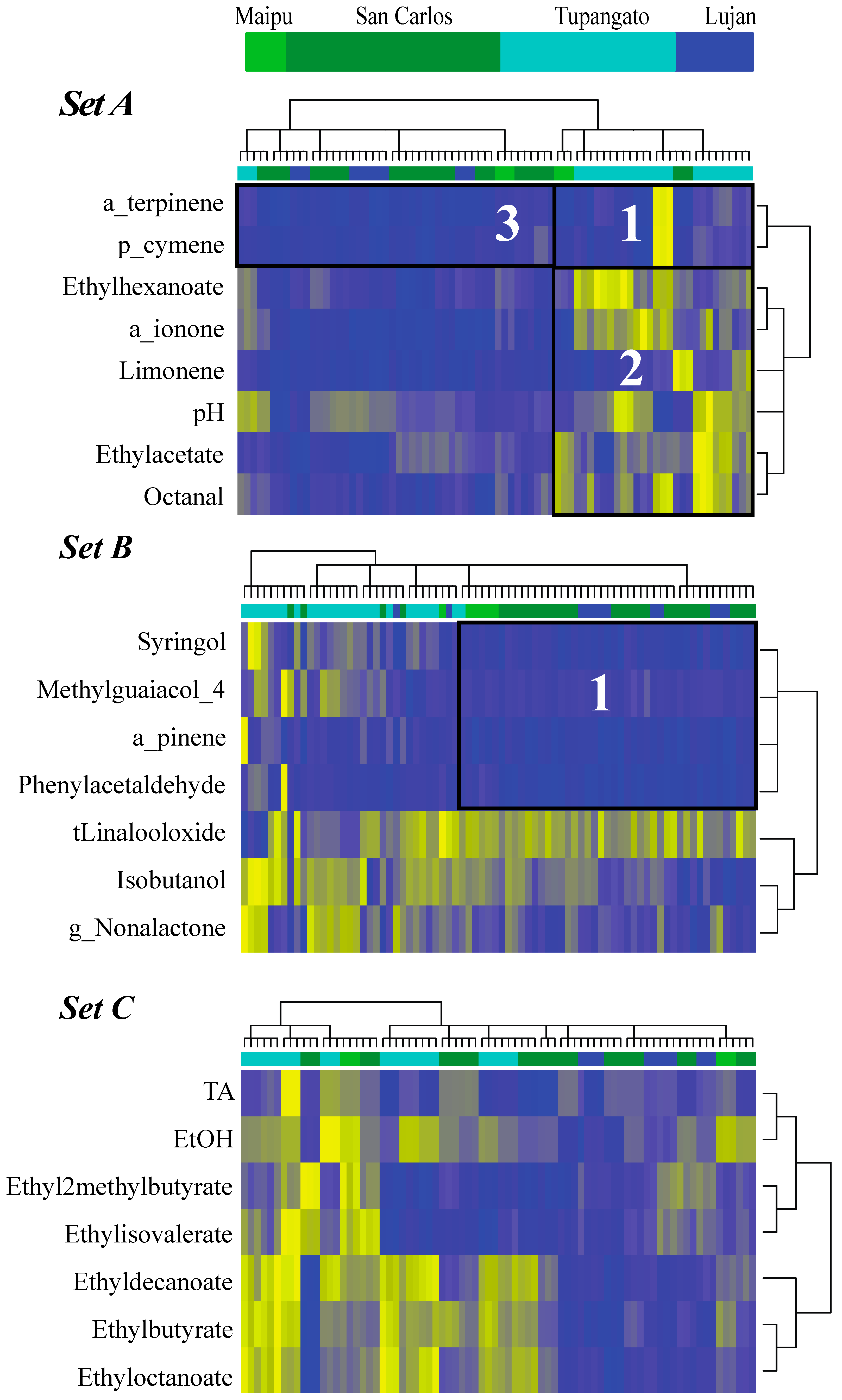
4.3. Argentinean Malbec Wines
5. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Johnson, H.; Robinson, J. The World Atlas of Wine, 7th ed.; Mitchell Beazley Publishing: London, UK, 2013. [Google Scholar]
- Goldner, M.; Zamora, M. Sensory characterization of Vitis vinifera cv. Malbec wines from seven viticulture regions of Argentina. J. Sens. Stud. 2007, 22, 520–532. [Google Scholar] [CrossRef]
- Dengis, J. Manual del vino Argentino; SACI: Buenos Aires, Argentina, 1995. [Google Scholar]
- Robinson, J. The Oxford Companion to Wine, 3rd ed.; Oxford University Press: Oxford, UK, 2006. [Google Scholar]
- Shanken, M. The U. S. Wine Market: Impact Databank Review and Forecast; M. Shanken Communications: New York, NY, USA, 2010. [Google Scholar]
- Famularo, B.; Bruwer, J.; Li, E. Region of origin as choice factor: Wine knowledge and wine tourism involvement influence. Int. J. Wine Bus. Res. 2010, 22, 362–385. [Google Scholar] [CrossRef]
- Robinson, A.; Adams, D.; Boss, P.; Heymann, H.; Solomon, P.; Trengove, R. Influence of geographic origin on the sensory characteristics and wine composition of Vitis vinifera cv. Cabernet Sauvignon wines from Australia. Am. J. Enol. Vitic. 2015, 63, 467–476. [Google Scholar] [CrossRef]
- Cadot, Y.; Caillé, S.; Thiollet-Scholtus, M.; Samson, A.; Barbeau, G.; Cheynier, V. Characterisation of typicality for wines related to terroir by conceptual and by perceptual representations. An application to red wines from the Loire Valley. Food Qual. Pref. 2012, 24, 48–58. [Google Scholar] [CrossRef]
- Garcia-Carpintero, E.; Sanchez-Palomo, E.; Gallego, M.; Gonzalez-Vinas, M. Volatile and sensory characterization of red wines from cv. Moravia Agria minority grape variety cultivated in La Mancha region over five consecutive vintages. Food Res. Int. 2011, 44, 1549–1560. [Google Scholar] [CrossRef]
- Williamson, P.; Robichaud, J.; Francis, I. Comparison of Chinese and Australian consumers’ liking responses for red wines. Aust. J. Grape Wine Res. 2012, 18, 256–267. [Google Scholar] [CrossRef]
- Lund, C.; Thompson, M.; Benkwitz, F.; Wohler, M.; Triggs, C.; Gardner, R.; Heymann, H.; Nicolau, L. New Zealand Sauvignon Blanc distinct flavour characteristics: Sensory, chemical, and consumer aspects. Am. J. Enol. Vitic. 2009, 60, 1–12. [Google Scholar]
- González, G.; Nazrala, J.; Beltrán, M.; Navarro, A.; Borbón, L.D.; Senatra, L.; Albornoz, L.; Hidalgo, A.; López, M.; Gez, M.; Marcado, L.; Poetta, S.; Alberto, M. Characterization of wine grape from different regions of Mendoza (Argentina). Rev. De La Fac. De Cienc. Agrari. 2009, 41, 165–175. [Google Scholar]
- Fanzone, M.; Peña Neira, A.; Jofré, V.; Assof, M.; Zamora, F. Phenolic characterization of Malbec wines from Mendoza province (Argentina). J. Agr. Food Chem. 2010, 58, 2388–2397. [Google Scholar] [CrossRef] [PubMed]
- Fanzone, M.; Zamora, F.; Jofré, V.; Assof, M.; Gómez-Cordovés, C.; Peña Neira, A. Phenolic characterisation of red wines from different grape varieties cultivated in Mendoza province (Argentina). J. Sci. Food Agr. 2012, 92, 704–718. [Google Scholar] [CrossRef] [PubMed]
- Fabani, M.; Arrúa, R.; Vázquez, F.; Diaz, M.; Baroni, M.; Wunderlin, D. Evaluation of elemental profile coupled to chemometrics to assess the geographical origin of Argentinean wines. Food Chem. 2010, 119, 372–379. [Google Scholar] [CrossRef]
- Paola-Naranjo, R.D.; Baroni, M.; Podio, N.; Rubinstein, H.; Fabani, M.; Badini, R.; Inga, M.; Ostera, H.; Cagnoni, M.; Gallegos, E.; et al. Fingerprints for main varieties of Argentinean wines: Terroir differentiation by inorganic, organic, and stable isotopic analyses coupled to chemometrics. J. Agr. Food Chem. 2011, 59, 7854–7865. [Google Scholar] [CrossRef]
- Aruani, A.; Quini, C.; Ortiz, H.; Videla, R.; Murgo, M.; Prieto, S. Argentinean commercial Malbec wines: Regional sensory profiles. Obs. Vitivinic. Argent. 2012, 10, 1–9. [Google Scholar]
- Buscema, F.; Boulton, R. Phenolic Composition of Malbec: A Comparative Study of Research-Scale Wines between Argentina and the United States. Am. J. Enol. Vitic. 2015, 66, 30–36. [Google Scholar] [CrossRef]
- Nelson, J.; Hopfer, H.; Gilleland, G.; Cuthbertson, D.; Boulton, R.; Ebeler, S. Elemental Profiling of Malbec Wines Made under Controlled Conditions by Microwave Plasma Atomic Emission Spectroscopy. Am. J. Enol. Vitic. 2015, 66, 373–378. [Google Scholar] [CrossRef]
- King, E.; Stoumen, M.; Buscema, F.; Hjelmeland, A.; Ebeler, S.; Heymann, H.; Boulton, R. Regional sensory and chemical characteristics of Malbec wines from Mendoza and California. Food Chem. 2014, 143, 256–267. [Google Scholar] [CrossRef] [PubMed]
- Guyon, I.; Elissef, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 389–422. [Google Scholar]
- Hsieh, F.; McAssey, M. Time, temperature and data cloud geometry. Phys. Rev. E 2010, 82, 061110. [Google Scholar]
- Fushing, H.; Wang, H.; der Waal, K.V.; McCowan, B.; Koehl, P. Multi-scale clustering by building a robust and self-correcting ultrametric topology on data points. PLoS ONE 2013, 8, e56259. [Google Scholar] [CrossRef]
- Fushing, H.; Chen, C. Data mechanics and coupling geometry on binary bipartite network. PLoS ONE 2014, 9, e106154. [Google Scholar] [CrossRef]
- Fushing, H.; Hsueh, C.; Heitkamp, C.; Matthews, M.; Koehl, P. Unravelling the geometry of data matrices: Effects of water stress regimes on winemaking. J. R. Soc. Interface 2015, 12, 20150753. [Google Scholar] [CrossRef]
- Fushing, H.; Liu, S.Y.; Hsieh, Y.C.; McCowan, B. From patterned response dependency to structured covariate dependency: Categorical-pattern-matching. PLoS ONE 2018, 13, e0198253. [Google Scholar] [CrossRef] [PubMed]
- Fushing, H.; Roy, T. Complexity of possibly-gapped histogram and Analysis of Histogram. R. Soc. Open Sci. 2018, 5, 171026. [Google Scholar] [CrossRef]
- Mémoli, F. The Gromov-Wasserstein distance: A brief overview. Axioms 2014, 3, 335–341. [Google Scholar] [CrossRef]
- Mémoli, F. On the use of Gromov-Hausdorff Distances for Shape Comparison. In Eurographics Symposium on Point-Based Graphics; Botsch, M., Pajarola, R., Chen, B., Zwicker, M., Eds.; The Eurographics Association: Geneva, Switzerland, 2007; pp. 256–263. [Google Scholar]
- Mémoli, F. Spectral Gromov-Wasserstein distances for shape matching. In Proceedings of the IEEE 12th International Conference Computer Vision Workshops (ICCV), Kyoto, Japan, 27 September–4 October 2009; pp. 256–263. [Google Scholar]
- Ghahramani, Z. Probabilistic machine learning and artifical intelligence. Nature 2015, 521, 452–459. [Google Scholar] [CrossRef] [PubMed]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. Introduction to Statistical Learning; Springer: New York, NY, USA, 2013. [Google Scholar]
- Fan, J.; Samworth, R.; Wu, Y. Ultrahigh dimensional feature selection: Beyond the linear model. J. Mach. Learn. Res. 2009, 10, 2013–2038. [Google Scholar]
- Tan, M.; Inor, W.; Wang, L. Towards ultrahigh dimensional feature selection for big data. J. Mach. Learn. Res. 2014, 15, 1371–1429. [Google Scholar]
- Bolon-Canedo, V.; Sanchez-Marono, N.; Alonso-Betanzos, A. Recent advances and emerging challenges of feature selection in the context of big data. Knowl. -Based Syst. 2015, 86, 33–45. [Google Scholar] [CrossRef]
- Jordan, M.; Mitchell, T. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]






© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fushing, H.; Lee, O.; Heitkamp, C.; Heymann, H.; Ebeler, S.E.; Boulton, R.B.; Koehl, P. Unraveling the Regional Specificities of Malbec Wines from Mendoza, Argentina, and from Northern California. Agronomy 2019, 9, 234. https://doi.org/10.3390/agronomy9050234
Fushing H, Lee O, Heitkamp C, Heymann H, Ebeler SE, Boulton RB, Koehl P. Unraveling the Regional Specificities of Malbec Wines from Mendoza, Argentina, and from Northern California. Agronomy. 2019; 9(5):234. https://doi.org/10.3390/agronomy9050234
Chicago/Turabian StyleFushing, Hsieh, Olivia Lee, Constantin Heitkamp, Hildegarde Heymann, Susan E. Ebeler, Roger B. Boulton, and Patrice Koehl. 2019. "Unraveling the Regional Specificities of Malbec Wines from Mendoza, Argentina, and from Northern California" Agronomy 9, no. 5: 234. https://doi.org/10.3390/agronomy9050234