Kafka Connect: WHY (exists) and HOW (works)
Recently while exploring some ingestion technologies, I got chance to look into Kafka Connect (KC) in detail. As a developer, the 2 things that intrigued my mind were:
- WHY it exists : With Kafka already around,why do we need KC, why should we use it, what different purpose it serves.
- HOW it works: How it does what it does, internal code flow, distributed architecture, how it guarantees fault tolerance, parallelism, rebalancing, delivery semantics, etc
If you too have the above two questions in mind, this post might be helpful to you.
Note: My findings about the HOW part are based out of my personal understanding of KC source code, have not actually run it yet, so take it with pinch of salt. Corrections are welcome!
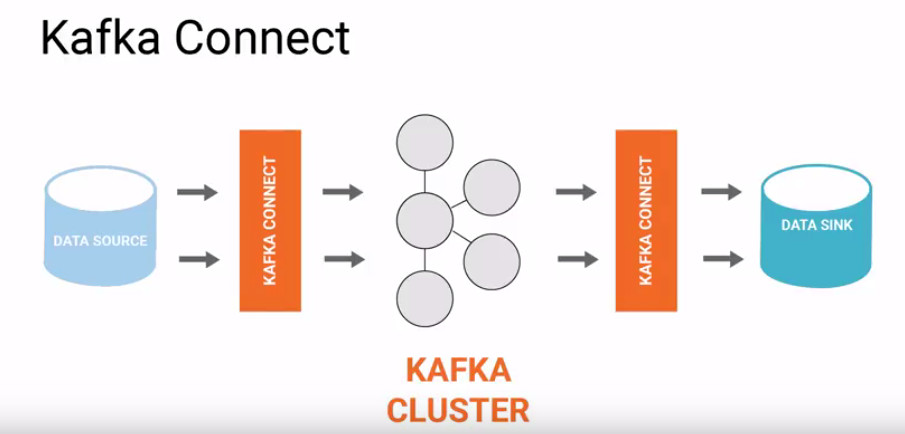
Intro about Kafka Connect:
Kafka Connect is an open source framework, built as another layer on core Apache Kafka, to support large scale streaming data:
- import from any external system (called Source) like mysql,hdfs,etc to Kafka broker cluster
- export from Kafka cluster to any external system (called Sink) like hdfs,s3,etc
For the above 2 mentioned responsibilities, KC works in 2 modes:
- Source Connector : imports data from a Source to Kafka
- Sink Connector : exports data from Kafka to a Sink

The core code of KC framework is part of Apache Kafka code base as another module named “connect”. For using Kafka Connect for a specific data source/sink, a corresponding source/sink connector needs to be implemented by overriding abstraction classes provided by KC framework (Connector, Source/Sink Task,etc). Most of the times it is being done by companies or community associated with the specific data source/sink like hdfs,mysql,s3,etc and then reused by application developers. KC assumes that at least one side, either source or sink has to be Kafka.
WHY Kafka Connect:
KC brings a very important Dev principle in play in ETL pipeline development:
SoC (Separation of Concerns)
An ETL pipeline involves Extract,Transform and Load. Any stream processing engine like Spark Streaming, Kafka Streams, etc is specialised for T (Transform) part, not for E (Extract) and L (Load). This is where KC fills in. Kafka Connect takes care of the E and L, no matter which processing engine is there, provided Kafka is part of the pipeline. This is great because now the same code of E and L for a given source/sink can be used across different processing engines. This ensures decoupling and reusability.
KC reduces friction and effort in implementing any Stream processing framework like Spark Streaming by taking up how-to-ingest-data responsibility .
Also, since Kafka is either on source or sink side for sure, we have better guarantees like parallelism,fault tolerance,delivery semantics,ordering,etc.
Important Question:
Do we get any benefits if we change code in existing ETL pipelines to use KC ? e.g. instead of Direct Kafka APIs in spark streaming, does it make sense to use KC for data ingestion?
The answer is NO. But if we use KC, we do get the flexibility of changing data source system at any time in future without changing stream processing code. This responsibility takeover by KC gives better flexibility to stream processing systems. This is what SoC is.
HOW Kafka Connect works:
Though KC is part of Apache Kafka download, but for using it, we need to start KC daemons on servers. It is important to understand that KC cluster is different from Kafka message broker cluster, KC has its own dedicated cluster where on each machine, KC daemons are running (java processes called as Workers).
A KC worker instance is started on each server with a Kafka broker address, topics for internal use and group id. Each worker instance is stateless and does not share info with other workers. But they coordinate with each other, belonging to same group id, via the internal kafka topics. This is similar to how Kafka consumer group works and is implemented underneath in a similar way.
Each worker instantiates a Connector (Source or Sink Connector) which defines configurations of the associated Task(Source or Sink Task). A Task is actually a runnable thread which does the actual work of transferring data and committing the offsets. e.g. S3SinkTask is a runnable thread which takes care of transferring data from Kafka of a single topic-partition to S3.
Worker instantiates pool of Task threads,based on info provided by Connector. Before creating task threads, Workers decide among themselves which part of data each of them is going to process, through internal Kafka topics.
It is important to note here, that there is no central server in KC cluster and KC is not responsible for launching worker instances, or restarting them on failure.
If a worker process dies, the cluster is rebalanced to distribute the work fairly over the remaining workers. If a new worker is started, a rebalance ensures it takes over some work from the existing workers. This rebalancing is an existing feature of Apache Kafka.
KC exposes REST api to create, modify and destroy connectors.
A Source Connector (with help of Source Tasks) is responsible for getting data into kafka while a Sink Connector (with help of Sink Tasks) is responsible for getting data out of Kafka.
Internally, what happens is, at regular intervals, data is polled by source task from data source and written to kafka and then offsets are committed. Similarly on the sink side, data is pushed at regular intervals by Sink tasks from Kafka to destination system and offsets are committed. For example, I looked into the code of S3sink connector and found that, a sink task keeps putting data for a specific kafka topic-partition to bytebuffer and then at a configurable time (by default 30 seconds), the data is accumulated and written to S3 files. Also, it uses a deterministic partitioner which ensures that in case of failures, even if the same data is written twice, the operation is idempotent. Deterministic partitioner means that a for a given same set of records, there will be same number of files with each file having exactly same data. As such, it ensures Exactly once delivery semantics.
The following diagram shows how a Sink Connector works. More info here.

Comparison with alternatives:
Any other streaming ingestion framework like Flume, Logstash (as far as I googled) will use some internal buffering mechanism of data before writing to destination. That buffering might or might not be reliable, might be local to node and so not fault tolerant in case of node failures. KC just makes it explicit that it either reads from Kafka Topic (Source) or write to a Kafka Topic (Sink) and it uses Kafka message broker underneath for data buffering. By doing that, it brings on table all those features like reliable buffering, scalability, fault tolerance, simple parallelism, auto recovery, rebalancing, etc for which Kafka is popular.
Apache Gobblin, well known reliable batch ingestion framework, is working on streaming ingestion development but is not available yet.
Also, KC is not only for ingestion but also for data export provided source of data is Kafka.
Why not Kafka Connect:
Like any other framework, KC is not suitable for all use cases . First of all, it is Kafka centric, so if your ETL pipeline does not involve Kafka, you can not use KC. Second, the KC framework is jvm specific and only supports Java/scala languages. Third and perhaps most importantly, Kafka Connect does not support heavy Transformation like Gobblin.
It is important to understand here that we can always write a custom connector which can do the Transformation as well but it is intentionally not encouraged by KC development guideline. Reason is simple, it does not want to mix the responsibility ........continue reading
Software Engineer at CBA
2yRegarding the kafka sink connector working, where the sink connector offsets commit details are stored? how do we can see that information? is any rest api's available for that?
Generative AI | Digital Transformation | Innovator | Entrepreneur
5yShould we be using KC if we need to ingest larger files into Kafka from some source