



Fine-tuning a Large Language Model (LLM) comes with tons of benefits when compared to relying on proprietary foundational models such as OpenAI’s GPT models. Think about it, you get 10x cheaper inference cost, 10x faster tokens per second, and not have to worry about any shady stuff OpenAI’s doing behind their APIs. The way everyone should be thinking about fine-tuning, is not how we can outperform OpenAI or replace RAG, but how we can maintain the same performance while cutting down on inference time and cost for your specific use case.
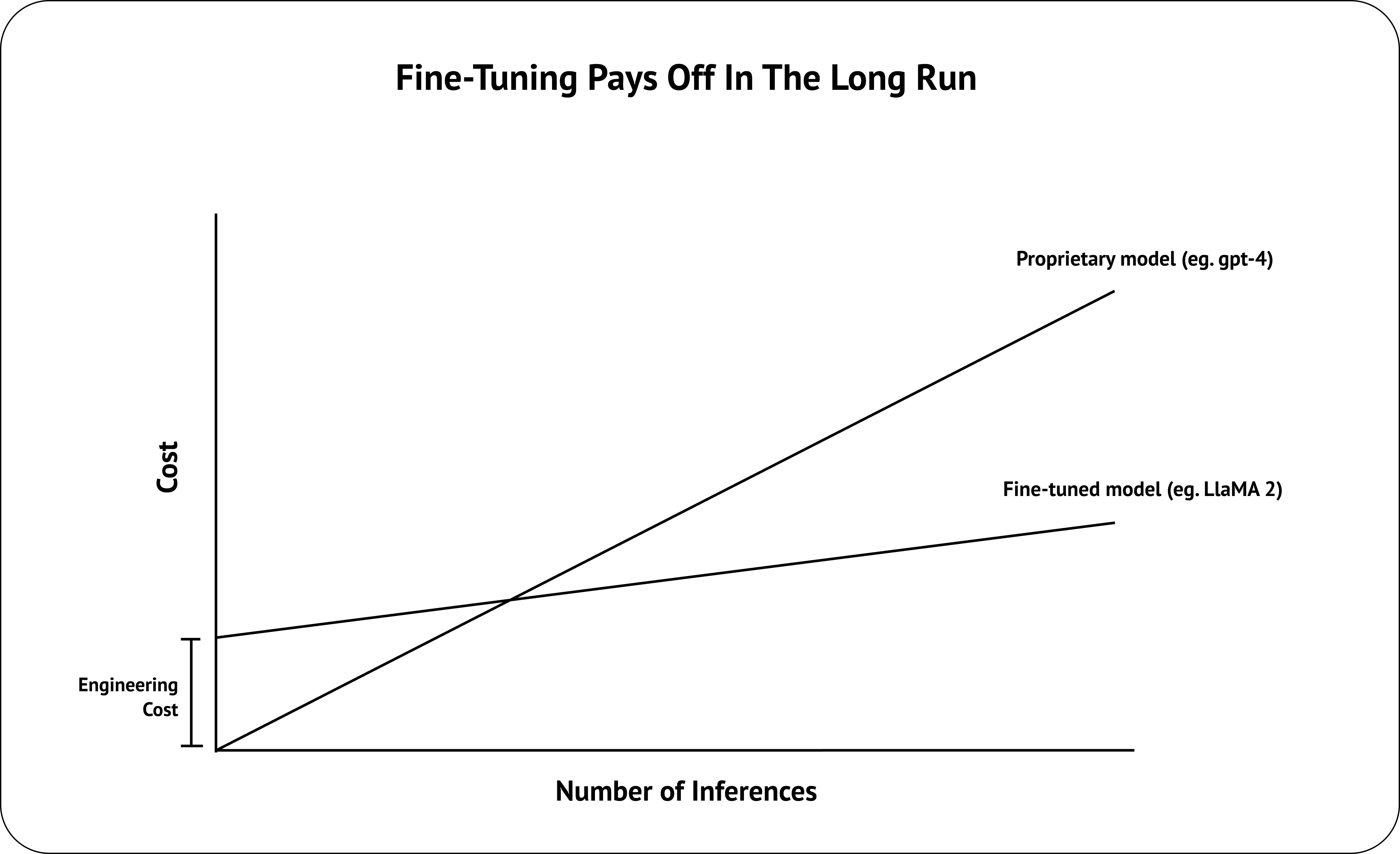
But let’s face it, the average Joe building RAG applications isn’t confident in their ability to fine-tune an LLM — training data are hard to collect, methodologies are hard to understand, and fine-tuned models are hard to evaluate. And so, fine-tuning has became the best vitamin for LLM practitioners. You’ll often hear excuses such as “Fine-tuning isn’t a priority right now”, “We’ll try with RAG and move to fine-tuning if necessary”, and the classic “Its on the roadmap”. But what if I told you anyone could get started with fine-tuning an LLM in under 2 hours, for free, in under 100 lines of code? Instead of RAG or fine-tuning, why not both?
In this article, I’ll show you how to fine-tune a LLaMA-3 8B using Hugging Face’s transformers library and how to evaluate your fine-tuned model using DeepEval, all within a Google Colab.
Let’s dive right in.
What is LLaMA-3 and Fine-Tuning?
LLaMA-3 is Meta’s second-generation open-source LLM collection and uses an optimized transformer architecture, offering models in sizes of 8B and 70B for various NLP tasks. Although pre-trained auto-regressive models like LLaMA-3 predicts the next token in a sequence fairly well, fine-tuning is necessary to align their responses with human expectations.
Fine-tuning in machine learning involves adjusting a pre-trained model’s weights on new data to enhance task-specific performance by training it on a task-specific dataset to adapt its responses to new inputs, and in the case of fine-tuning LLaMA-3, this means giving it a set of instructions and responses to employ instruction-tuning to make it useful as assistants. Fine-tuning is great because, did you know it took Meta 1.3M GPU hours to train LLaMA-3 8B alone?
Fine-tuning comes in two different forms:
- SFT (Supervised Fine-Tuning): LLMs are fine-tuned on a set of instructions and responses. The model’s weights will be updated to minimize the difference between the generated output and labeled responses.
- RLHF (Reinforcement Learning from Human Feedback): LLMs are trained to maximize the reward function (using Proximal Policy Optimization Algorithms or the Direct Preference Optimization (DPO) algorithm). This technique uses feedback from human evaluation of generated outputs, which in turn captures more intricate human preferences, but is prone to inconsistent human feedback.
As you may have guessed, we’ll be employing SFT in this article to instruction-tune a LLaMA-3 8B model.
Common Pitfalls in Fine-Tuning
Poor Training Data
The previous statement on RLHF sheds light on a very important point: The quality of the training dataset is the most important factor when it comes to fine-tuning. In fact, the LIMA paper shown that fine-tuning a 65B LLaMA (1) on 1,000 high-quality samples can outperform OpenAI’s DaVinci003.
Consider another example, which is a fine-tuned gpt-3.5-turbo on 140k slack messages:

It’s pretty hilarious, but maybe only because it’s not coming from my LLM.
Using The Wrong Prompt Template
This actually only matters if you’re using a specific models that was trained on a specific prompt template, such as LLaMA-2’s chat models. In a nutshell, Meta used the following template when training the LLaMA-2 chat models, and you’ll ideally need to have your training data in this format.
For these reasons, we’ll be using the mlabonne/guanaco-llama2–1k dataset for fine-tuning. It is a set of 1000 high quality instruction-response dataset (derived from the timdettmers/openassistant-guanaco dataset) in LLaMA-2's prompt template reformat.
A Step-By-Step Guide to Fine-Tune LLaMA-3
Step 1 — Installation
To begin, create a new Google Colab notebook. That’s right, we’ll be doing everything in a Colab notebook.
Then, install and import the required libraries:
Here, we’re using libraries from the Hugging Face and Confident AI ecosystem:
transformers: to load models, tokenizers, etc.peft: to perform parameter efficient fine-tuningbitsandbytes: to setup 4-bit quantizationtrl: for supervised fine-tuningdeepeval: to evaluate the fine-tuned LLM
Step 2— Quantization Setup
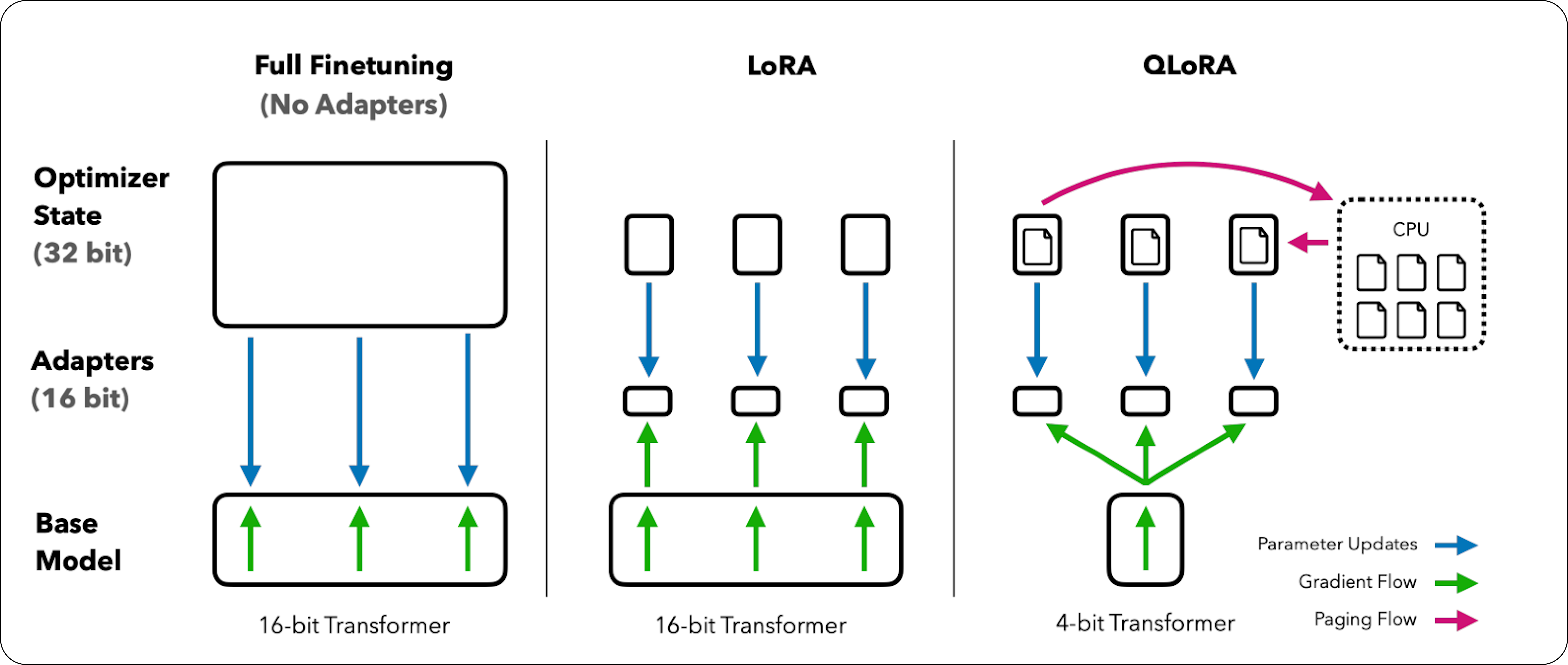
To optimize Colab RAM usage during LLaMA-3 8B fine-tuning, we use QLoRA (quantized low-rank approximation). Here’s a breakdown of its key principles:
- 4-Bit Quantization: QLoRA compresses the pre-trained LLaMA-3 8B model by representing weights with only 4 bits (as opposed to standard 32-bit floating-point). This significantly shrinks the model’s memory footprint.
- Frozen Pre-trained Model: After quantization, the vast majority of LLaMA-3’s parameters are frozen. This prevents direct updates to the core model during fine-tuning.
- Low-Rank Adapters: QLoRA introduces lightweight, trainable adapter layers into the model’s architecture. These adapters capture task-specific knowledge without drastically increasing the number of parameters.
- Gradient-Based Fine-tuning: During the fine-tuning process, gradients flow through the frozen 4-bit quantized model but are used to update solely the parameters within the low-rank adapters. This isolated optimization greatly reduces computational overhead.
Here’s a visual representation of QLoRA from the original paper.
As an implementation, we can take advantage of the bitsandbytes library:

Confident AI: Everything You Need for LLM Evaluation
An all-in-one platform to evaluate and test LLM applications, fully integrated with DeepEval.
.png)

Step 3 — Load LLaMA-3 with QLoRA Configuration
This step is pretty straightforward. We will simply load the LLaMA-3 8B model from Hugging Face.
Note that although LLaMA-3 is open-source and available on Hugging Face, you’ll have to send a request to Meta to gain access which typically takes up to a week.
Step 4 — Load Tokenizer
When an LLM reads text, it first has to convert the text to a readable format. This process is known a tokenization, which is carried out by a tokenizer.
Tokenizers are usually designed to work with their respective models. Copy the following code to load the tokenizer for LLaMA-3:
Step 5 — Load Dataset
As explained in the previous section, we’ll be using the mlabonne/guanaco-llama2–1k dataset for fine-tuning given its high quality data labels and compatibility with LLaMA-3's prompt templates.
Step 6 — Load LoRA Configurations for PEFT
I’m not going to go into the detailed differences between QLoRA and LoRA, but LoRA is essentially a less memory-efficient version of QLoRA since it does not use quantization, but may yield slightly higher accuracy. (You can read more about LoRA here.)
In this step, we configure LoRA for parameter efficient fine-tuning (PEFT), which updates a small subset of parameters in contrast to normal fine-tuning, where all model parameters are updated instead.
Step 7 — Set Training Arguments and SFT Parameters
We’re almost there, all that’s left is to set the arguments required for training and the supervised fine-tuning (SFT) parameters for the trainer:
I’m going to spare you from what all these parameters mean, but if you’re interested you can check out Hugging Face’s documentation:
Step 8 — Fine-Tune and Save Model
Run the following code to start fine-tuning:
You should expect the training to last up to an hour. Here’s an image of a wild LLaMA party to keep you entertained in the meantime :)

Once fine-tuning has completed, save your model and tokenizer, and you can start testing the results of your fine-tuned model immediately!
Evaluating a Fine-Tuned LLM with DeepEval
I know what you’re thinking (or at least I hope I do). You’re expecting some plot of loss over the course of fine-tuning on something like tensorboard, but fortunately I’m not going to bore you with this “evaluation” approach. Instead, we’ll be using DeepEval, an open-source LLM evaluation framework for LLMs.
Since we fine-tuned LLaMA-3 8B to essentially make them useful as assistants, we’ll evaluate our model based on 3 metrics: bias, toxicity, and helpfulness. In DeepEval, these metrics are evaluated using LLMs using a mixture of careful prompt engineering and frameworks such as QAG and G-Eval.
For those interested, here is another great read on the rationale behind why we’re using LLMs as evaluators. To begin, set your OpenAI API key and define LLM evaluation metrics:
DeepEval’s metrics returns a score (0–1) and provides a reason for its score. A metric is only considered successful if the computed score passes the threshold (which depending on the metric can either be a maximum or minimum threshold). For those wondering how these metrics are implemented, you can poke around ⭐ DeepEval’s open-source repo ⭐, or learn about everything you need to know about scoring an LLM evaluation metric.
To wrap things up, create a list of inputs you want to evaluate your model’s outputs on by creating test cases using DeepEval's synthetic data generator:
We hardcoded the inputs for simplicity, but you get the point. Lastly, create and evaluate your dataset using the LLM evaluation metrics you previously defined:
And you’re done! Congratulations for making to the end of this tutorial, but with this setup, you’ll be able to add additional metrics and test cases to further evaluate and iterate on your fine-tuned LLaMA-3.
PS. DeepEval also integrates with Hugging Face to allow real-time evaluations during fine-tuning.
Conclusion
In this article, we explored what LLaMA-3 is, why you should fine-tune and what it involves, and things to watch out for when fine-tuning, including using the right dataset, and formatting them to fit the prompt templates the base model was trained in.
We also saw how we can use the Hugging Face ecosystem to seamlessly carry out fine-tuning in a Google Colab notebook, using quantization techniques such as QLoRA. Lastly, we saw how the fine-tuned model can be evaluated using DeepEval ⭐. We’ve done all the hard work for you already, and offers an entire ecosystem for LLM fine-tuning evaluation.
Thank you for reading and as always, till next time.
Do you want to brainstorm how to evaluate your LLM (application)? Schedule a call with me here (it’s free), or ask us anything in our discord. I might give you an “aha!” moment, who knows?
Confident AI: Everything You Need for LLM Evaluation
An all-in-one platform to evaluate and test LLM applications, fully integrated with DeepEval.
.jpg)








