I’m going to use this blog post as a dynamic list of performance optimizations to consider when using Azure Data Factory’s Mapping Data Flow. I am going to focus this only to files. I will post subsequent articles that list ways to optimize other source, sinks, and data transformation types. As I receive more good practices, feedback, and other performance tunings, I will update this article accordingly.
Here is Azure SQL DB Optimizations for ADF Data Flows
Here is Azure SQL DW Optimizations for ADF Data Flows
Optimizations to consider when using ADF Mapping Data Flows with files
NOTE: When you are designing and testing Data Flows from the ADF UI, make sure to turn on the Debug switch so that you can execute your data flows in real-time without waiting for a cluster to warm up.

You can control how many partitions that ADF will use
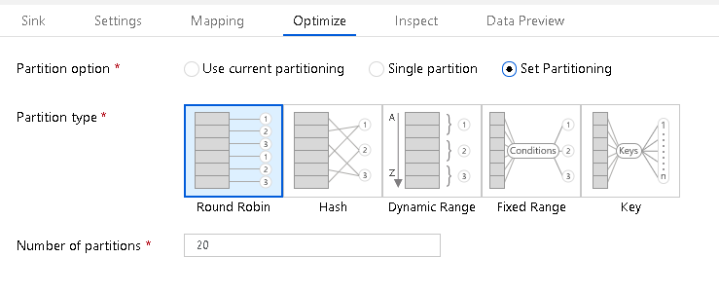
- On each Source & Sink transformation, as well as each individual transformation, you can set a partitioning scheme.
- For smaller files, you may find selecting “Single Partition” can sometimes work better and faster than asking Spark to partition your small files.
- If you do not have enough information about your source data, you can choose “Round Robin” partitioning and set the number of partitions.
- If you explore your data and find that you have columns that can be good hash keys, use the Hash partitioning option.
File naming options
- The default nature of writing transformed data in ADF Mapping Data Flows is to write to a dataset that has a Blob or ADLS Linked Service. You should set that dataset to point to a folder or container, not a named file.
- Data Flows use Azure Databricks Spark for execution, which means that your output will be split over multiple files based on either default Spark partitioning or the partitioning scheme that you’ve explicitly chosen.
- A very common operation in ADF Data Flows is to choose “Output to single file” so that all of your output PART files are merged together into a single output file.
- However, this operation requires that the output reduces to a single partition on a single cluster node.
- Keep this in mind when choosing this popular option. You can run out of cluster node resources if you are combining many large source files into a single output file partition.
- To avoid this, you can keep the default or explicit partitioning scheme in ADF, which optimizes for performance, and then add a subsequent Copy Activity in the pipeline that merges all of the PART files from the output folder to a new single file. Essentially, this technique separates the action of transformation from file merging and achieves the same result as setting “output to single file”.
Increase size of your compute engine in Azure Integration Runtime
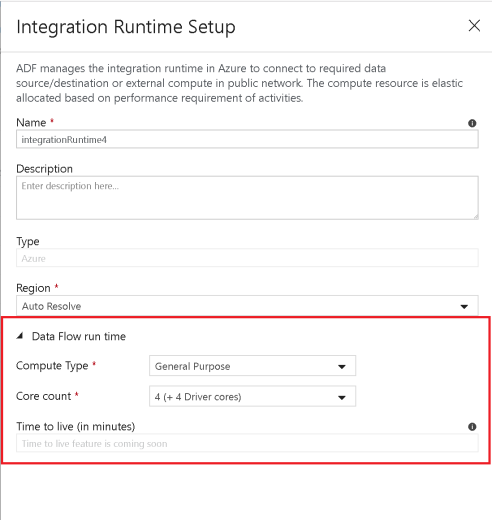
- Increase the number of cores, which will increase the number of nodes, and provide you with more processing power to process your file operations.
- Try “Compute Optimized” and “Memory Optimized” options.
